How Node.js Works Behind the Scenes
After you complete this article, you will have a solid understanding of:
- How the Node.js Event Loop works, including all of its phases
- How Node.js executes JavaScript code in a single-threaded environment
- How Node.js uses the libuv library and internal APIs to manage asynchronous operations
- Why understanding the Event Loop is crucial for writing efficient backend code
If you know how JavaScript works behind the scenes in the browser environment (I highly recommend you check this 15-minute read article if you don't know), it's relatively easier to understand unlike Node.js. It doesn't have a bunch of phases or so on.
But why does Node.js have different, and complicated phases, just to make things harder to understand?
In the browser, JavaScript only needs to handle basic things like user interactions, timers, and promises. So it only uses a task queue and a microtask queue, which is enough for that environment. It handles these kinds of operations with the help of Web APIs.
Note: If you are not familiar with task queue and microtask queue, as I said before - and promise will say for the last time - you can check this 15-minute explanation about how JavaScript works
But Node.js is not just JavaScript - it's a full runtime designed to run JavaScript anywhere! There is nothing like Web APIs that can help it. That runtime has to work on our servers so it also deals with files, network requests, and low-level system tasks. Because of this, Node.js needs a more complex event loop with multiple phases to handle all these different types of operations properly.
Node.js has to make JavaScript work everywhere with good performance. So it has to handle what browsers handle for us plus some extra server-side events that are very important to be handled properly!
While in web browsers, things like fetch requests are sent to the Web API, in Node.js this works a bit differently. In Node.js, the equivalent of the "Web API" concept is actually a C/C++ library called "libuv" - they're not perfectly equal but think like they both try to make JavaScript asynchronous.
Note: I will be using the term "I/O" a lot in this article. I/O means Input-Output, so it refers to any operation where data goes in or out to/from outside of our world - like reading a file, sending a request, or receiving a response.
Web API in web browsers:
- It's an interface provided by the browser itself.
- Implemented by browser manufacturers (Chrome, Firefox, Safari, etc.) in languages like C++.
- Each browser has its own Web API implementation.
- Works within the browser, using the browser's resources.
libuv in Node.js:
- It's a C library used by Node.js to manage asynchronous I/O operations.
- Directly uses the operating system's APIs.
- Abstracts operating system-specific mechanisms (IOCP on Windows, epoll on Linux, etc.).
- An independent component that comes with Node.js.
Key difference: While Web API works within the browser, libuv directly accesses operating system resources. Both manage asynchronous operations but work in different environments.
In terms of request handling:
- In Web API: Requests wait in the browser's own subsystems.
- In Node.js: Requests wait in the operating system's I/O queues.
In both cases, JavaScript's main thread isn't blocked, but requests are managed at different layers. While the web browser manages the process within its own resources and processes, Node.js works more directly with the mechanisms provided by the operating system.
And again in both cases, the operating system is the main mechanism that monitors and notifies when I/O operations are completed. The operating system detects network responses, file operations, and other I/O events using hardware interrupts and system calls.
Now, you have some idea about how Node.js actually handles things differently from JavaScript. If you didn't completely get it, that's all fine! We will go step by step from the very basic concepts, to understand everything clearly.
Node Execution
The Node runtime is just a C++ program that takes an input, and the input is a JavaScript file. Node reads that file and interprets that JavaScript. JS Code is executed line by line serially until it's done.
But the real world isn't all sunshine and rainbows. Our JavaScript code is not just read line by line and finishes. There are some situations that may, and will happen. For example, we can say execute this part of code after X milliseconds. So until those milliseconds have passed, we need to wait. Or we may read a file from the external world, and after reading a file is done, only then we might want to execute some code. Or let's say our JavaScript code is listening on a port, and someone is connected to us. So we can't just terminate the program, right? We need to wait. When a user is connected to us, we don't even know when they're going to send a request. But when they do, we immediately need to take action, right? So serial execution - executed line by line serially - does not work anymore.
So we have something like a loop to check if some things are happening or not. Because when they happen, our code needs to take action immediately.
That's why we have something called an event loop.
Note: Before we dive into the event loop, there is another term that you need to know, and it's callback. Callback functions are functions that need to execute when a specific event happens. So when we specify a timer, we also specify a callback which will execute after the timer has finished. Or we say go read this file, and after reading, you need to execute this function. As the name says "Call back" - calling back a function after some event happens.
Event loop is a loop with different phases. Each phase has a queue of callbacks. And our code will terminate itself when there are no callbacks left in these queues. Don't worry about the details for right now. Because we will deep dive into the main loop and its every phase. You will have a clear understanding.
Event Loop (Simplified)
The event loop is what allows Node.js to perform non-blocking I/O operations — despite the fact that a single JavaScript thread is used by default — by offloading operations to the system kernel whenever possible.
So when initial code execution happens, we start reading the code line by line. If we see any async operation on our way (Reading a file, Network Connection, Timers...) we register the callback. We don't execute its callback! We just register it so that when our event happens at a later time, we can execute it. Callbacks may register more callbacks too. Maybe we said go read a file after 5 seconds, and boom our callback registered another callback. We have to keep running our code after these callback queues are empty.
So what we do is, execution -> go to callback queue -> execution -> go to callback queue... until there are no callbacks to call.
But remember, this loop starts after execution of initial code! Execution of the initial code can also be considered a phase.
Now, let's go over all these phases of our code execution. We will learn what's happening in our code step by step.
The Main Module
First, we start with The Main Module. This is where we don't have a loop yet, this is the initial phase - if you want to call it a phase, you may not want to either, I won't blame you.
The initial phase will run only once at the begging of our code execution!
In the main module, all code executes synchronously. No callbacks can get executed, and the main loop is not yet initialized. We will register callbacks, but we won't execute them in this phase. Main module = initial phase.
const x = 1;
const y = x + 1;
setTimeout(() => console.log("Should run in 1ms"), 1);
for (let i = 0; i < 10000000; i++);
console.log("When this will be printed?");
So, what do you think the output will be? If you read what I just wrote carefully, you probably guessed it right.
When this will be printed?
Should run in 1ms
It's the main module and there are no callbacks executed in this phase! It's the initial phase, and the initial execution of our code.
Most of the time (if you use require) other modules will be resolved before the initial phase even starts. If other modules have other modules inside them, then they have to wait for those modules to be loaded. And we have to wait for all of the modules to be loaded.
We need to keep the initial phase as short as possible. Keeping the initial phase short is great for performance, since it spins up Node faster. So using too many modules in our code is almost never a good thing.
Well, technically since the loop hasn't even started in the initial phase - main module - you can prefer not to say it was a "phase". But now, the loop is going to start! And the loop's first phase will be the timer phase. With this phase starting, we will have the event loop that we've talked about at the beginning. Now, we will see every step, and these will be the steps that we will go through:
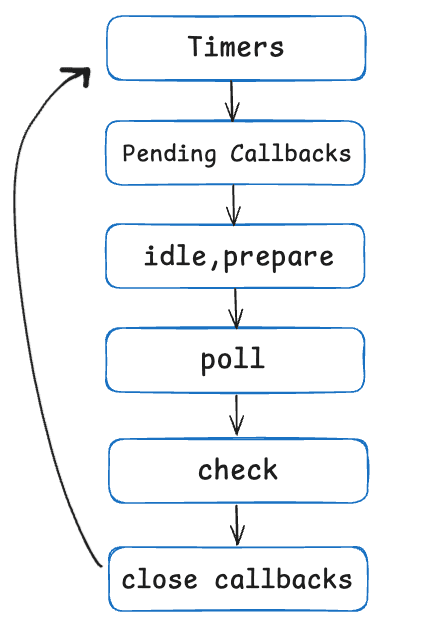
Each box will be referred to as a "phase" of the event loop.
Each phase has a FIFO (First in, first out) queue of callbacks to execute. While each phase is special in its own way, generally, when the event loop enters a given phase, it will perform any operations specific to that phase, then execute callbacks in that phase's queue until the queue has been exhausted or the maximum number of callbacks has executed. When the queue has been exhausted or the callback limit is reached, the event loop will move to the next phase, and so on.
This multi-phase approach allows Node.js to prioritize different types of asynchronous operations efficiently, which is very important for server-side applications that handle many I/O operations like file system access, network requests, and database queries. The browser's simpler model works well for user interface interactions, while Node.js's more complex model and phases are optimized for server-side operations where different types of I/O tasks need different handling priorities.
Before we deep dive into every step, let's look at an overview so you may have an idea before you start understanding the detail of every step.
Phases Overview
In Node.js, the event loop continuously iterates through all six phases in sequence. This constant circulation ensures that all types of asynchronous operations are properly handled, with the event loop checking each phase for pending tasks before moving to the next one, and then starting over again from the beginning once it completes a full cycle.
How these 6 phases are placed in their own positions is very important. They are not just randomly placed 6 phases, they all have specific phases for a lot of reasons. And when we go in detail, you will learn some of the reasons why some loops are placed after/before other phases.
-
Timers: This phase executes callbacks scheduled by
setTimeout()andsetInterval(). -
Pending Callbacks: This is where Node.js deals with "leftover" callbacks from the previous loop, especially those related to system operations. These are typically callbacks related to system operations like TCP error handling.
-
idle, prepare: These are internal phases that Node.js uses for its own housekeeping. The idle phase is where Node.js might perform some internal cleanup tasks when the loop has nothing else to do. The prepare phase is where Node.js gets ready to enter the poll phase, setting up anything needed before checking for new I/O events.
-
Poll: This is arguably the most important phase. Here, Node.js:
- Looks for new I/O events (like incoming network connections or file operations)
- Executes callbacks for those I/O events that are ready
- May temporarily pause here ("block") to wait for new events if there's nothing else to do.
The poll phase is essentially where Node.js spends most of its time, waiting for and responding to external events like network requests or file operations.
-
Check: This is specifically where
setImmediate()callbacks run.setImmediate()is a special timing function in Node.js that lets you schedule a callback to run immediately after the poll phase. It's useful when you want to execute code right after any pending I/O operations but before any new timers. -
Close Callbacks: This final phase handles cleanup callbacks - specifically those related to closing resources like sockets or file handles. For example, when a network connection closes, the socket's 'close' event callback would run in this phase.
It's okay if you didn't understand at all what actually happens in every phase. Because we will learn all of them in detail starting right now! After you completed this blog, I want you to come back in this part, and read it again. You will see how much you actually learned.
Phases in Detail
Timers Phase
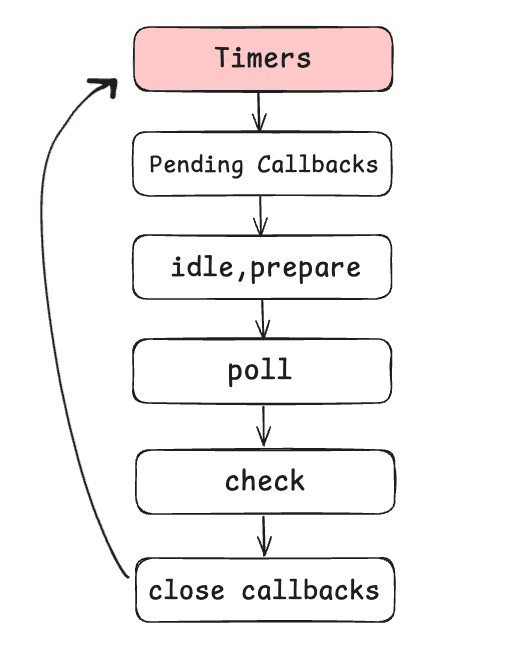
Timers phase starts right after the initial phase. This is where the event main loop actually gets initialized. And the first phase in the loop is timers. It's done by the underlying library called libuv.
Timer callbacks get scheduled, sorted by duration.
But they are not 100% accurate! They can be slowed down by our operating system, and also by other phases too. For example, if we're doing a heavy operation in the initial phase, that means our timer has to wait at least until that heavy operation ends. So when we say, run this function after 10 milliseconds, it can run it maybe even after 2 seconds. That's why we say they are not accurate.
Now, let's see a code example to understand everything better. We are going to set some timers, and see if they actually work when the "correct" time passes.
First, let's see how setTimeout function works.
setTimeout(timerCallback, 100, "100 ms", 100);
When we define a setTimeout function in Node.js, the first argument will be the function that will be executed after the second argument milliseconds. The third and fourth arguments are arguments that are passed to the timerCallback function. So:
const timerCallback = (a, b) =>
console.log(`Timer ${a} delayed for ${Date.now() - start - b}`);
const start = Date.now();
setTimeout(timerCallback, 500, "500 ms", 500);
setTimeout(timerCallback, 0, "0 ms", 0);
setTimeout(timerCallback, 1, "1 ms", 1);
setTimeout(timerCallback, 1000, "1000 ms", 1000);
for (let i = 0; i <= 1000000000; i++);
Note: arguments "a", and "b" will take the third and fourth arguments in the setTimeout function.
In this example, we are trying to find how many milliseconds they have been delayed.
First, we take the time by defining a start variable to find the exact time when we started the initial phase. And inside the timerCallback function, we take the Date.now(). This Date.now() will give us the exact time that the function has executed, right? So if we say Date.now() - start time when the function is executed, we should get 500ms for the first function, 0ms for the second function, 1ms for the third function, 1000ms for the fourth function. Because they should work after "second argument" ms.
So function execution's time - start time = the time that has passed until they executed.
In this example, b gives us how many ms they will be delayed. So, Date.now() - start - b should be equal to 0.
Well, that's not really true though. Because when you work with timers, you will always be delayed by something. By your operating system, by other phases... Remember, before we go into the loop, we have the initial phase. In the initial phase, these functions are registered but not called! So first we have to be done with the initial phase. And that's why at least we will be delayed because of the initial phase. That's because there is some "heavy" operation going on in the initial phase. (for loop to demonstrate)
So our output will be:
Timer 0 ms delayed for 437
Timer 1 ms delayed for 442
Timer 500 ms delayed for 2
Timer 1000 ms delayed for 2
We can say, our heavy operation in the initial phase took ~437ms. Because the timer that should run immediately (after 0ms), ran after 437ms. That's why our second (1ms timer) has delayed too. (Since Node.js is single threaded, they have to wait for each other!) But it didn't delay 438ms as expected. It's delayed 442ms so it's even 4ms more. This proves what we've said, timers are not 100% accurate.
Now, we go into the third phase. (second phase in the loop, third phase overall). And it's called Pending Callbacks.
Pending Callbacks
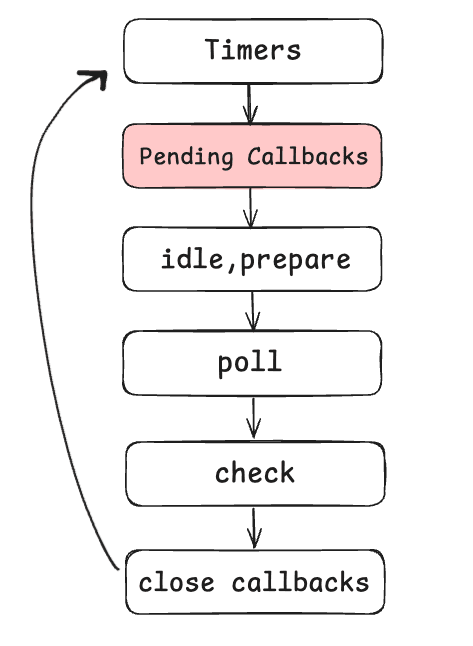
The pending callbacks phase is specifically responsible for executing callbacks that were delayed from previous loop iterations, typically those related to I/O operations (for example like TCP connection errors).
Here's what happens during this phase:
- When certain system operations (like TCP errors) occur in the poll phase - which is another phase that you will learn - their callbacks get scheduled for execution in this phase.
- Node.js processes these pending callbacks one after another until either the queue is empty or the system-specific limit is reached.
Think of it as a "cleanup" phase where Node.js handles callbacks that were deferred from previous operations.
Like we said, in each iteration, the pending callbacks phase processes callbacks that were deferred from previous iterations. So when a callback is deferred, it will be processed in the pending callbacks' phase of the next iteration.
Let's say you're building a web server that needs to handle many connections:
const http = require("http");
const fs = require("fs");
// Create a server
const server = http.createServer((req, res) => {
// Reading a file (I/O operation)
fs.readFile("large-file.txt", (err, data) => {
if (err) {
// If there's an error, this callback might be deferred to pending callbacks phase. (To be executed for the next iteration!)
console.error("Error reading file:", err);
res.statusCode = 500;
res.end("Server error");
return;
}
res.statusCode = 200;
res.end(data);
});
});
// If there's an error with TCP connection
server.on("error", (err) => {
// This callback will likely be processed in the pending callbacks phase
console.error("Server error:", err);
});
server.listen(3000, () => {
console.log("Server running on port 3000");
});
In this example, if there's a TCP error in the server, or if the file reading operation encounters issues, those error callbacks might be processed during the pending callbacks phase rather than immediately.
Here is a takeout you should take from this phase:
If an error happens, that error's callback function won't be executed until a later time. (Until the next iteration's pending callback phase)
But what if we processed errors immediately instead of deferring them? That's an excellent question about the design choices in Node.js. If we tried to handle all errors immediately in their original phase (like the poll phase) instead of deferring some to the pending callbacks phase, several important consequences would occur:
- Blocking the Event Loop: The most significant issue would be potential blocking of the event loop. Some system-level errors and callbacks might require substantial processing time. By handling everything immediately, the event loop could get stuck processing these operations, preventing it from moving on to other tasks.
- I/O Starvation: During the poll phase - which you will learn in detail about what poll phase is in a minute - Node.js is primarily focused on waiting for and handling new I/O events. If complex error handling occurred here, it could delay the processing of other incoming connections or events, potentially causing timeouts or dropped connections.
But remember, when we defer a callback to the pending callbacks phase, we're not magically eliminating the processing time it requires - we're just moving it to a different phase of the event loop. So why is this helpful? Because it can still block the event loop when the next iteration happens, right?
By moving certain callbacks to the pending callbacks phase, Node.js gains control over when these potentially heavy operations occur within the event loop cycle. This creates a more predictable performance pattern. The pending callbacks phase is strategically placed after timers but before the poll phase, which means:
- Time-sensitive timer callbacks get executed first
- Heavy system callbacks run before returning to I/O polling
Node.js and libuv - library that powers Node.js' event loop and provides cross-platform access to asynchronous I/O operations - apply limits to how many pending callbacks are processed in each iteration. If there are too many, some will be deferred to the next iteration. This is crucial because:
// Internally, libuv might do something like:
while (pendingQueue.length > 0 && processedCallbacks < MAX_CALLBACKS_PER_ITERATION) {
const callback = pendingQueue.shift();
callback();
processedCallbacks++;
}
This prevents the pending callbacks phase from completely dominating a single iteration of the event loop.
So every phase has some kind of unique control to prevent blocking behavior for the event loop. If "some operations" can be in the "right phase", then it makes everything much more manageable.
Note: There is an exception for some cases. When using Node.js to establish TCP connections, the order in which you see success and error callbacks can sometimes be unexpected due to how the event loop handles these operations. Error callbacks might execute before success callbacks if:
Failed connections often fail quickly - if a server doesn't exist or a port is closed, the system can determine this almost immediately. So in this case, you might not see error callback after success callback as you might have expected. Since it fails so quickly, the event loop won't register it to the pending callbacks phase and instead it will just run that callback immediately.
On the other hand, there are several situations where error callbacks might appear later (after success callbacks) when working with TCP connections in Node.js, and one of them is Timeout-based failures:
When a connection attempt doesn't receive any response, it may need to wait for the timeout period (which could be several seconds) before triggering the error callback. In these cases, you will see success callbacks trigger before error callbacks, even if the error connection was initiated first in your code.
Okay we've spent enough time on the pending callbacks phase. Now, let's deep dive into another phase which is called Idle, prepare.
Idle, prepare phase
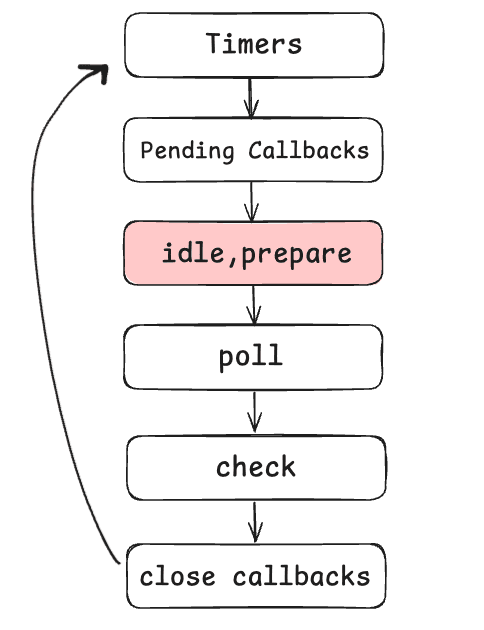
This is the phase right after pending callbacks, our third (fourth overall) phase in the event loop. This phase is an internal phase for Node. Not for us users actually.
So we have 2 different steps in one phase. When it comes to idle, there is not much we can talk about actually. Like I said, it's for Node's internal tasks. And of course, it runs in every iteration.
But for the prepare step, it is an important step in Node.js's event loop that occurs immediately after the Idle step and before the Poll phase. During this step, the event loop prepares for potential upcoming events and executes certain types of scheduled callbacks.
The main purpose of the Prepare step is to execute callbacks that need to run before the Poll phase starts polling for I/O events. This is a strategic moment in the event loop cycle when Node.js can perform necessary setup operations before potentially blocking for I/O in the upcoming Poll phase.
These callbacks are not your own callbacks, but ones used by Node.js to get things ready. For example, it may set up timers or prepare network events. This phase helps make sure everything is in place before the event loop starts polling for new activity.
For example, let's say you spin up a TCP server.
const net = require('net');
const server = net.createServer((socket) => {
socket.end('Hello world\n');
});
server.listen(3000);
Before the event loop enters the poll phase, Node.js may run some internal setup code during the prepare phase. This setup ensures the server is ready to accept new connections. These are not user-defined callbacks, but internal operations handled by Node.js to manage the underlying system behavior.
Now, let's go into the phase right after idle, prepare. Our fourth (fifth overall) phase in the event loop.
Poll phase
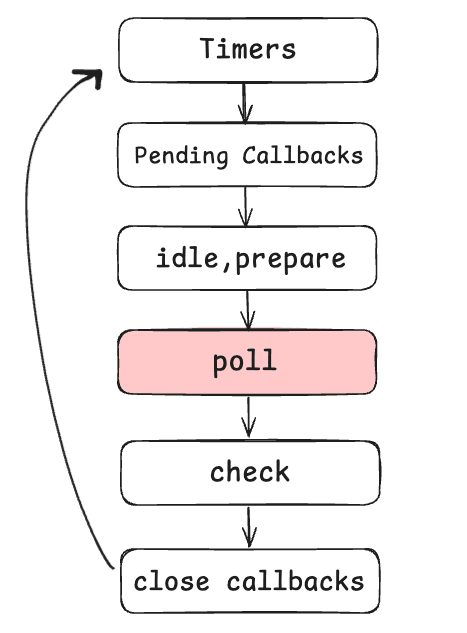
This phase is called the poll phase, and this phase is probably the most important phase in our event loop.
Two important things happen during this phase:
-
Node.js checks for I/O events Think of it like this: Node.js constantly asks, "Is there anything new?" Similar to a waiter walking around a restaurant asking, "Do you need anything?" Node.js, as a waiter, checks for:
- Any incoming network requests
- Any completed file reading/writing operations
- Any new connection requests
For example, when a user visits your website or when you want to read a file, Node.js sends these requests to the operating system and waits for results. The poll phase is where Node.js checks for these results.
-
Callbacks for completed operations are executed When an operation finishes (like a file being read or a network request arriving), Node.js runs the function (callback) associated with that operation. For example:
onRead: When a file finishes reading, we might log something to the consoleonConnected: When a connection is established, we perform a specific actiononListen: When a socket begins listening, we execute particular code
Dynamic imports (using import()) are also processed during this phase.
There's something crucial you should understand: Node.js can actually block in the poll phase. This means the event loop might pause here waiting for I/O events.
When your Node.js application has nothing else to do, it will stay in the poll phase, waiting for I/O callbacks to come in. The poll phase will block (wait) until either:
- An I/O event triggers its callback
- A timer (from the timers phase) becomes due
- There are setImmediate callbacks waiting to be executed
This blocking behavior is intentional and allows Node.js to efficiently wait for work to arrive rather than constantly spinning through the event loop phases when nothing needs to be done. (You will have a better understanding when you read the next phase, which is check phase. So bear with me!)
While Node.js blocks in the poll phase, it's important to understand this doesn't mean your entire application is frozen. This is "good blocking" - efficiently waiting for the next task.
However, you should be careful with CPU-intensive operations during callbacks executed in this phase. For example:
// This could block the entire event loop if the file is large
fs.readFile('large-file.txt', (err, data) => {
// CPU-intensive operation in the callback
const result = performComplexCalculation(data);
console.log(result);
});
Note: For CPU-intensive tasks, we can consider using:
- Worker threads - It's not in the context of this blog, but you can try to google it and learn. -
- Child processes - It's not in the context of this blog, but you can try to google it and learn. -
- Breaking work into smaller chunks using
setImmediate()-setImmediate()is a function that you will learn in the next phase! -
So the poll phase is where Node.js spends most of its time when your application is handling I/O operations like:
- Handling HTTP requests
- Reading/writing database data
- Processing file operations
Now, let's go into our next phase which is the Check Phase.
Check Phase
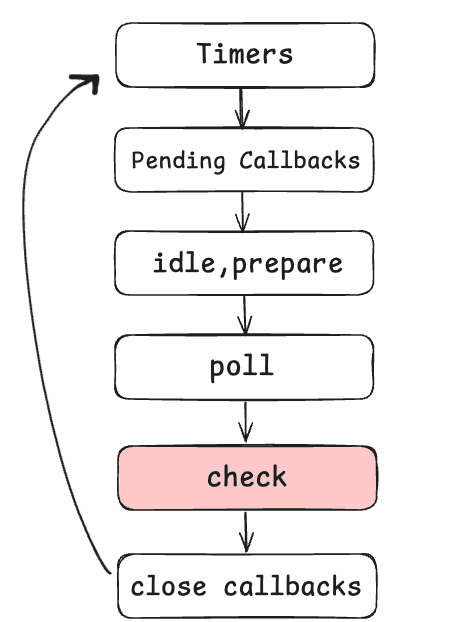
This phase, unlike idle and prepare, is a phase that we have "control" over as users. We can schedule callbacks to be executed exactly in this phase. Right after the poll phase, so right after the I/O operations.
setImmediate is the function to schedule check phase callbacks. We use it for deterministic outcomes. Because we know that this function will be executed right after the poll phase.
It's okay if you don't fully get it, because now, you will after this example.
Let's say we have the following code:
const readFileCallback = (err, data) => {
console.log(`readFileCallback ${data}`);
};
const f = "test.txt";
fs.readFile(f, readFileCallback);
setImmediate(() => console.log("setImmediate called!"));
Let's analyze what happens when we run this code.
First, we start with the initial phase, right? We register everything in the initial phase but we don't read the file or execute the callback yet! Because it's poll phase's responsibility! So we've scheduled these events (read the file, and execute the callback) for the poll phase.
We are still in the initial phase! We aren't done reading our code and scheduling things for the appropriate phases.
Now, our initial phase saw setImmediate() function, what is it going to do? It will schedule this callback for the check phase.
Now, the initial phase is done. Then we go to timer phase, nothing happens as there are no timers. Then we go to pending callbacks, is there anything to do? No, then move on. Then idle, prepare. Node.js may do some internal work but it's not our job. Then, finally move to the poll phase.
There are 2 things to do in the poll phase. First thing is, we need to read the file, and we need to execute the callback, right? Before we have to execute the callback, we have to issue the read operation. After we issued the file read, now Node.js will immediately move on to the next phase because there is a setImmediate() function that is waiting to be executed in the check phase. Because Node.js doesn't want to spend time and wait (block) the event loop for both read and execute operations.
So it will move to the check phase, it will print setImmediate called to the console, and loop all the way back to the timers phase, and poll phase again. By the time we come back to the poll phase again, let's assume the read process has completed. So we will execute the poll phase's callback now, in the second loop.
Here's what actually happens:
Node.js enters the poll phase. It checks with the operating system: "What I/O operations have completed?". For each completed operation, it executes the associated callback right away. If there are no callbacks waiting in the poll phase, BUT: If there are setImmediate callbacks, it exits poll phase to handle them!
So, while Node.js does two main things in the poll phase (checks for completed I/O events and executes callbacks for those completed events), it doesn't continuously wait in the poll phase for each individual I/O operation to complete. Instead, it queries the operating system for any I/O operations that have already completed since the last check.
There is one important thing you should know! If the file didn't exist, that means we would not be able to issue the file read, and in that particular case, our callback function would be executed immediately. So the setImmediate() function wouldn't be executed first!
But this all makes sense. Because if the file doesn't exist, then there will be no "heavy" reading operation so we are not going to block the event loop anyway. That's why there is no point to go to the check phase first.
So try the code below, and see for yourself how the outputs will look like!
test.txt file exists:
const fs = require(`fs`);
const readFileCallback = (err, data) => {
console.log(`readFileCallback ${data}`);
};
const f = "test.txt";
fs.readFile(f, readFileCallback);
setImmediate(() => console.log("setImmediate called!"));
Output will be:
setImmediate called!
readFileCallback
test123.txt file does not exist:
const fs = require(`fs`);
const readFileCallback = (err, data) => {
console.log(`readFileCallback ${data}`);
};
const f = "test123.txt";
fs.readFile(f, readFileCallback);
setImmediate(() => console.log("setImmediate called!"));
Output will be:
readFileCallback undefined
setImmediate called!
Now, we move to our final phase! Which is the Close Callbacks phase.
Close Callbacks Phase
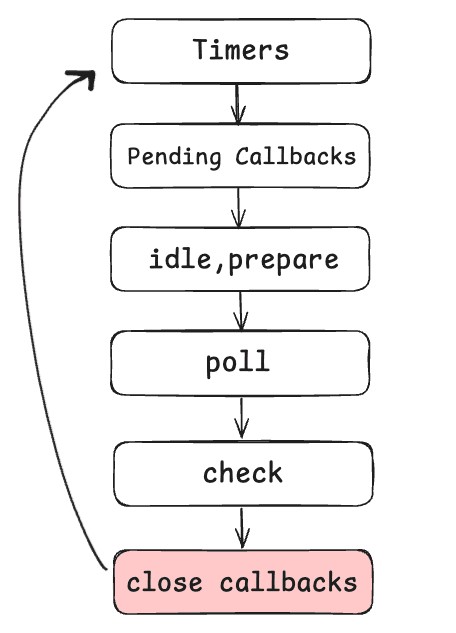
After Node.js has handled all the timers, I/O callbacks, idle checks, and immediate callbacks, there's one final stop in the event loop: the close callback phase.
Think of Close Callbacks as Node's way of doing final cleanup before it's done processing. When you close a server or a socket connection, Node.js needs to make sure everything is properly shut down.
The Close Callbacks phase specifically handles callbacks that are triggered by events like:
- A TCP server closing with
server.close() - A socket connection ending with
socket.on('close', ...) - A process exiting normally
Let's say you have a net.Socket, and you attach a .on('close', ...) listener to it. That function doesn't run right away when the socket closes. It waits for this special phase to fire.
Let's see in an example.
const net = require("net");
const server = net.createServer((socket) => {
console.log("Client connected");
socket.on("close", () => {
console.log("Socket closed – this runs in the close callback phase");
});
// Close the socket after 2 seconds
setTimeout(() => {
socket.end(); // Triggers 'close'
}, 2000);
});
server.listen(3000, () => {
console.log("Server listening on port 3000");
});
What's Happening Here?
- A client connects to the server.
- After 2 seconds, the server ends the socket connection.
- When that happens, the 'close' event is emitted.
- Node waits until it reaches the close callback phase of the event loop to actually run the callback for
.on('close', ...).
So that final console.log won't run immediately after .end(), it waits for Node to reach that phase.
Now, what I want you to do is, go back to the Phases Overview section, right before we started to dive deep into phases, and read it again. Now, you will see that you have a clear understanding about what happens in every phase.
We completed every phase but there is only one thing left to complete our event loop. And it's a phase that we've never talked about so far. It's like a "Hidden phase", and yes, we're talking about the process.nextTick().
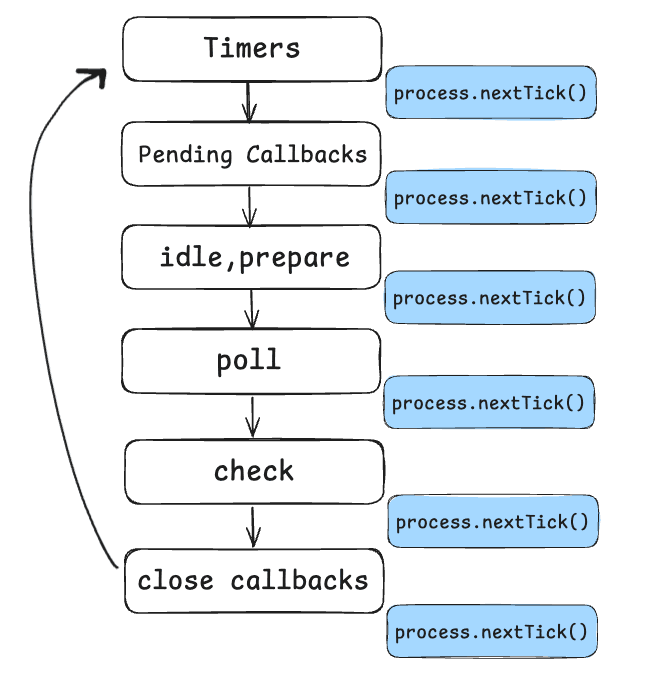
As you see in the image above, process.nextTick() is executed after every phase! Sounds crazy, right? So the actual event loop is something like timers -> process.nextTick() -> pending callbacks -> process.nextTick() ...
Actually it starts even before timers. Because before the event loop, we have the initial phase. process.nextTick() will work right after the initial phase too!
You may have noticed that process.nextTick() was not displayed in the first event loop diagram, even though it's a part of the asynchronous API. This is because process.nextTick() is not technically part of the event loop. Instead, the nextTickQueue will be processed after the current operation is completed, regardless of the current phase of the event loop.
process.nextTick() is actually very powerful. If you remember, before we go into the event loop, we have the "initial phase -main module-" right? After the initial phase is completed, only then do we start the event loop. So NextTick can tell us when the initial phase actually ends! We could set timers to see when the event loop started, -since timers are the first phase of the event loop- but timers can get delayed, so NextTick will give us more accurate results. It can be a good indicator to know when the initial phase really ends, and when the event loop is about to start.
Now, let's see some examples.
console.log("start");
for (let i = 0; i < 1000000; i++);
console.log("end");
setTimeout(() => console.log("timer"), 0);
process.nextTick(() => console.log("nextTick"));
So, what will be the output?
start
end
nextTick
timer
Why? Because right after the initial phase, NextTick will run, and only then will the event loop -so the timer phase- start!
Now, let's see the example below, and once again we will understand the power of Node.js.
let val;
function test() {
console.log(val);
}
test();
val = 1;
So, all the code is synchronous here. Nothing hard to understand. First, we initialize the variable val, but it's undefined. Then, before we say val=1, we call the function and that will print the val, but at that time in the code, val is undefined. So we will see undefined in the console. But what if we can fix it in a very cool way?
let val;
function test() {
console.log(val);
}
process.nextTick(test);
val = 1;
Now, what do you think will happen? process.nextTick() won't be executed within the initial phase, but it will get executed right after the initial phase! So, it will be executed after we assign value 1 to it. So this time, even though code placement is completely the same, now we see 1 in the console!
There are two main reasons to use process.nextTick():
- Allow users to handle errors, cleanup any then unneeded resources, or perhaps try the request again before the event loop continues.
- At times it's necessary to allow a callback to run after the call stack has unwound but before the event loop continues.
One last thing you should know - I promise you, it's the last one - Promises in Node.js operate within the microtask queue of the event loop, but with a lower priority than process.nextTick callbacks. When a Promise is resolved, its .then() handlers are queued as microtasks to be executed after all nextTick callbacks have completed, but before the event loop moves on to the next phase like timers or I/O operations. This prioritization ensures that Promise chains execute in a predictable order while maintaining the non-blocking nature of Node.js.
If you know How Javascript Works Behind The Scenes in a web environment, in terms of Node.js equivalents:
Browser's macrotask queue → Distributed across different phases in Node.js Browser's microtask queue → Used for Promise callbacks and process.nextTick() in Node.js
An important difference in Node.js: process.nextTick() operations are processed before other Promises in the microtask queue and are checked at the end of each phase.
I think now you fully understand how Node.js actually works behind the scenes!
Was this blog helpful for you? If so,