How JavaScript Works Behind the Scenes: A Visual Step-by-Step Guide to the Engine (2025)
After you complete this article, you will have a solid understanding of:
- How JavaScript executes code in a single thread
- What the Call Stack is and how it manages execution
- How Web APIs help with asynchronous operations
- The difference between Task Queue and Microtask Queue
- How the Event Loop coordinates all these components
As we all know JavaScript runs on just one thread, so it can only do one thing at a time. But somehow it handles many things at once. How does that work? It's like trying to text friends, make coffee, and watch Instagram reels, all with just one hand. If you've ever asked yourself how JavaScript does so many things without freezing even though it's single threaded, you're not alone. So let’s take a closer look at how this actually happens behind the scenes, and how the JS engine manages to pull off this kind of ‘multi-tasking’.
Let's do it step by step. First of all, JavaScript is not a "compiled" language so it doesn't directly translate to machine code like C, C++, or Go. We have to take the JavaScript file as an input, and we have to put it in some kind of machine that can understand that file and "interprets" it to machine code. As you probably know, that's what "interpreted languages" means. There are some upsides and downsides of being an interpreted language, but I'm not going into so much detail here so we don't get lost.
Some kind of machine in this context will be V8 Engine which Google Chrome or NodeJS uses (there are some other engines that can do the same job too). So basically, V8 Engine is a runtime that can take a JavaScript file as input and turn it into something computers can understand.
But like we said at the beginning, it runs on one thread. Why is that though?
So, this engine has mainly 2 parts called Heap, and Call Stack.
Heap part is the memory area where objects and variables are stored. Reference types (objects, arrays, functions etc.) are also stored in the heap. So this part is mainly for storage. Not to get too confused, let's forget this part for right now and let's focus on why JavaScript runs only on one thread.
The Call Stack, on the other hand, is the part that manages the execution of our program, and it’s also what makes JavaScript single-threaded. Let’s walk through a code example, step by step.
Let's say we have the following code to run;
console.log("First");
console.log("Second");
For the first console.log function, something called execution context is created(you can nevermind it for right now), pushed into the call stack, logged in the console then popped out from the call stack. For the second console.log it's the same story. A new execution context is created, pushed into the call stack, logged in the console and popped out from the call stack... Just like we said, everything happens one by one in the call stack. Single task at a time!
Note: For functions, the execution context means that every time a function is called, a new environment is created to handle that specific call. This environment stores: the function's local variables, arguments passed to the function, the value of the
thiskeyword (basically, whatthiskeyword points to in that context), and a reference to its outer (parent) scope for closure access. So basically, each function call runs in its own little ‘box’ with its own data. And we call that box the execution context to make it sound a bit cooler.
But what if we don’t just have simple console.logs, but some heavy operations going on? For example:
function veryHeavyOperation() {
for (let i = 0; i < 100_000_000_000; i++) {
console.log(
"there’s some heavy operation happening at the moment… can you be quiet?"
);
}
}
function veryImportantTask() {
console.log("This is a very important console.log!");
}
veryHeavyOperation();
veryImportantTask();
Now, before our important task works, we have to wait for the call stack to be available. Because there’s a really huge for loop, and it just doesn’t finish. In the meantime, our program is completely frozen. The reason? like we said 100 times-sorry but I think I'll probably keep saying it...-, javascript is single threaded.
But this is not actually what we want. In real world applications, we often do network requests, handle files operations, we wait for user inputs, we wait for timers and so on... We definitely can't block our call stack for all these operations.
To solve these problems, we use some tools.
First of these tools are WEB APIs. Web APIs provide us some functions to allow us to interact with browser's features. (features like fetch, setTimeout, console, Geolocation, HTMLElement, URL ...)
So our browser works very hard in the back scenes. It does rendering, it does our network services, and also it provides us an interface to allow us to access some of its other features. But what makes these WEB APIs useful for long running tasks? Some of the WEB APIs allow us to off-load long running tasks to the browser.
For example, let's use one of the web api's to see what really happens.
navigator.geolocation.getCurrentPosition(
(position) => console.log(position),
(error) => console.error(error)
);
Geolocation api allows the user to provide their location to web applications. First callback function that is passed to it means getting the location was successful. Other callback means some error happened during the process.
When the function is called, getCurrentPosition invocation is added to the call stack. But this is just to register those callback functions that we passed as parameters, and initiate that async task. After doing that, it will be popped out from the call stack. So it doesn't block the call stack. See below:
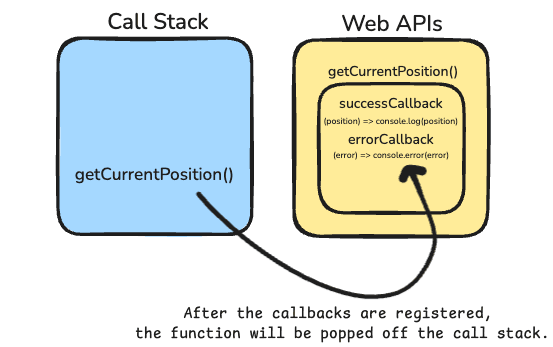
In the background, browser will start some kind of process and will ask the user for their location;
Well, we don't really know when user wants to allow. But that's not a problem. Since our function is not in call stack anymore, any other functions can still keep working in the call stack.
When, finally user clicks to allow, our API receives the data from browser, and uses the success callback to handle this result.
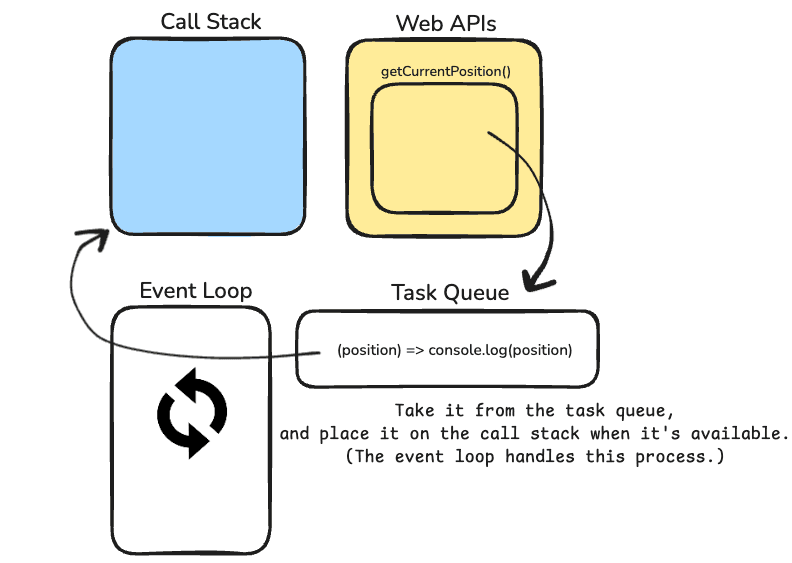
But, it can't just push that success function into the call stack. We don't know what's really happening in the call stack at this moment. It might interrupt some other process that are happening and it might cause some weird bugs. That's where other players come into play. Let's introduce Task Queue, also known as Callback queue. This queue holds web api callbacks and event handlers to be able to get executed at some point in the future. When is this future? Whenever call stack is available!
But how can we know when will call stack will be available? And now, to solve this problem, even another player comes into screen. And it's Event Loop. As the name says, it's a loop that checks the call stack continuously to see if it's available. If call stack is available, event loop will take the first available task from the task queue and moves it to the call stack. See below image;
Now, before we dive into the event loop, let's do another example. There is another very popular callback-based Web API called setTimeout(), which you might have heard of.
setTimeout() function will get a callback, and a timeout.
setTimeout(() => console.log("This will run after 1000 milliseconds"), 1000);
Let's say we have a code like this;
setTimeout(() => {
console.log("1000ms");
}, 1000);
setTimeout(() => {
console.log("2000ms");
}, 2000);
console.log("DeepIntoDev");
Just like we've seen before, first, setTimeout function will be added to the call stack. But this will only be to register that timeout (with its delay time). After registering the timeout, it will be popped out from the call stack. Same story, second timeout is going to be registered too. Now they are on the Web APIs side. They get registered and left the call stack.
Then, our console.log("DeepIntoDev") will go into the call stack. There is nothing asynchronous here, so it will just print DeepIntoDev to the console. After, it will be popped out from the callstack. Now, our final state looks like this;
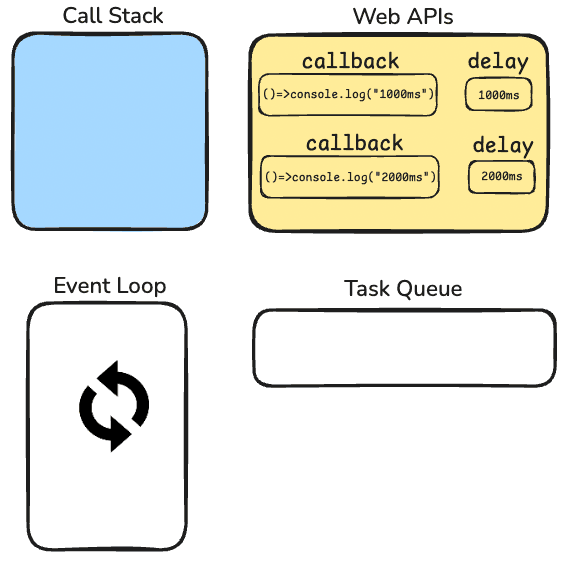
And our console looks like this at the moment;
DeepIntoDev
After 1000ms has passed, browser will say "Hey, 1000ms has passed", so the callback function which has 1000ms delay, will be moved to Task Queue;
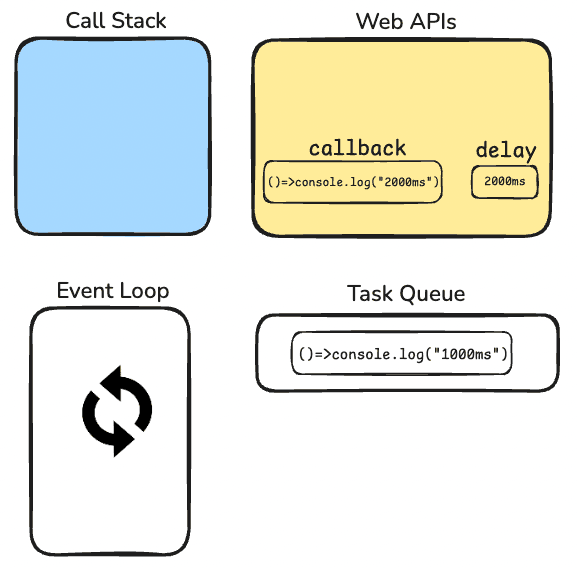
Since there is nothing going on in the call stack right now, event loop will take that function and put it into call stack. After 2000ms has passed, same story will happen.
But there is something really important that you need to be aware of. 1000 ms delay that we gave our function, is actually the delay of taking the function from web apis to task queue. It's not the delay that it will be executed on the call stack! So if call stack were busy, that function would have to wait. That means it was gonna be executed at a later point even after 1000ms has passed!
After ~2000ms has passed, our console will be like this;
DeepIntoDev
1000ms
2000ms
These examples we've seen until now were Callback-based APIs. There is also another approach to handling async operation in JavaScript and it's called Promise-based APIs. Callback-based APIs use functions passed as arguments that get executed after an asynchronous operation completes. On the other hand, promise-based APIs return Promise objects that represent future values. Here is an example for Promise-based API in JavaScript;
function fetchData(url) {
return new Promise((resolve, reject) => {
// Simulating network request
setTimeout(() => {
if (url === "invalid") {
reject(new Error("Failed to fetch data"));
} else {
resolve({ data: "Success" });
}
}, 1000);
});
}
// Then/catch approach
fetchData("example.com")
.then((result) => console.log("Result:", result))
.catch((error) => console.error("Error:", error));
// Async/await approach
async function getData() {
try {
const result = await fetchData("example.com");
console.log("Result:", result);
} catch (error) {
console.error("Error:", error);
}
}
We generally use promises for complex asynchronous flows, modern JavaScript applications, and better readability.
Note: If you're curious and if you want to learn how Promises work behind the scenes in JavaScript, you can take a look at this 10-minute blog about how Promises work in JavaScript
But what differences happen in the back-scene when we use promise-based apis instead of callback-based apis?
Whenever we work with promises, we're working with Microtask queue. So now, we've added 1 more tool to handle our async operation. Our final "components" look like this now;
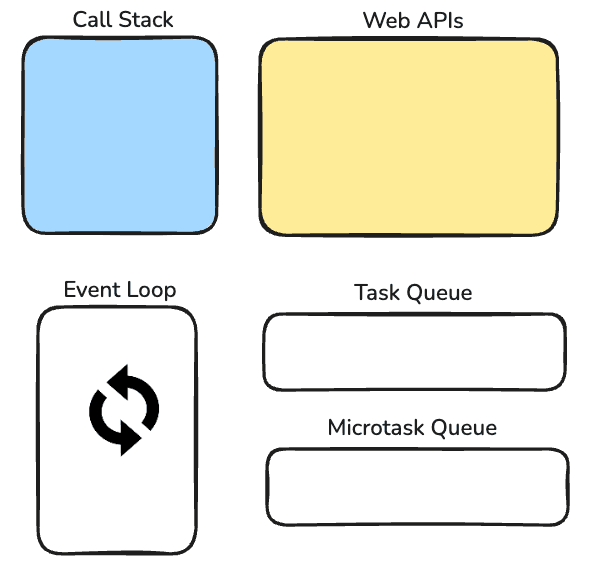
Microtask queue is a special queue that is dedicated to; .then, .catch, .finally callbacks and for async-await. Only these will get pushed into microtask queue. (There are also some other functions like queueMicrotask, new mutationObserver.)
There is something really important that you should know here. Event loop prioritizes Microtask Queue! So event loop will first look at the Microtask queue, if call stack is available, it will take those functions into the call stack. Only after when Microtask queue is empty, it will go and check the task queue.
More on that, event loop will check microtask queue after every event in the task queue! So when micro task queue is empty, it goes to task queue. It completes 1 task, and goes back to micro task queue. If it's empty then it goes to other task in task queue. Event loop will repeat this until both task queue and microtask queue are empty.
The most popular promised-based WEB API is fetch. As you already might know, the Fetch API is a modern JavaScript interface for making HTTP requests to servers. So let's do an example with using it.
fetch("https://mybackendserver.com/api/users/...").then((res) =>
console.log(res)
);
console.log("DeepIntoDev");
After we run the code above, fetch() function will be added to the callstack. But this is just to create the Promise Object. So function won't be executed but just registered to WEB APIs part, just like we saw at the callback-based apis. After, .then function will be added to the callstack, but this is just to register too. We will register a record so that we know what we do after our promise is resolved. (PromiseReaction)
Note: I know I already said it, but if you want to learn about this Promise Object in detail, you can check out this 10-minute blog post.
After fetch function is registered to the Web APIs, console.log("DeepIntoDev") will be added to the call stack and it will be executed right away since there is no asynchronous operation happening. Right now, our components look like this;
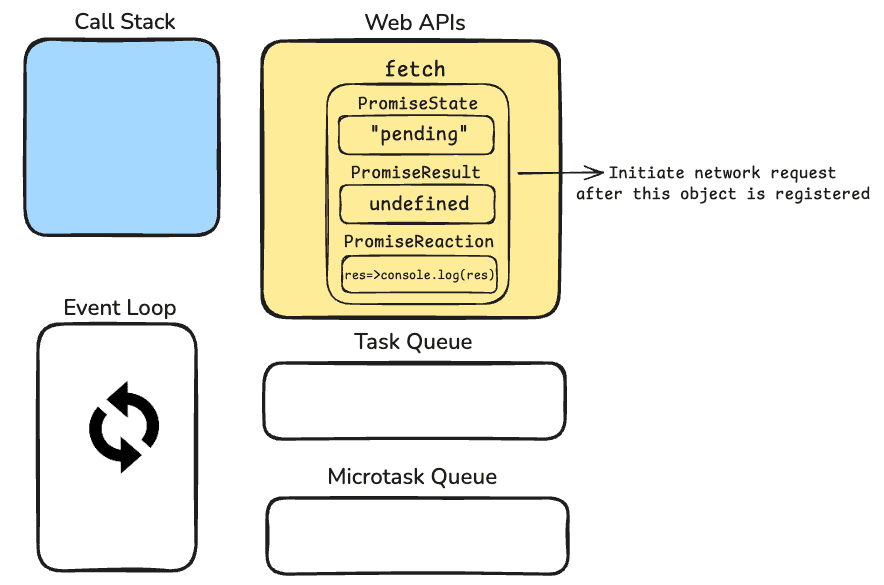
After we registered the promise object, browser will make a network request in the back scenes. Meantime, call stack is empty so we are not blocking any code that wants to go into call stack and get executed.
Note: If you're curious about how this request and communication happens between our browser and server from the other side of the world, I have a very cool blog about that — How Data Travels the World to Reach Your Screen
When finally server returned some data, our PromiseState which was "pending" state will turn to "fulfilled" and PromiseResult which was undefined will turn to Response Object with the data that we got from the server. And finally, our PromiseReaction will be pushed to Microtask Queue. So the final state looks like this;
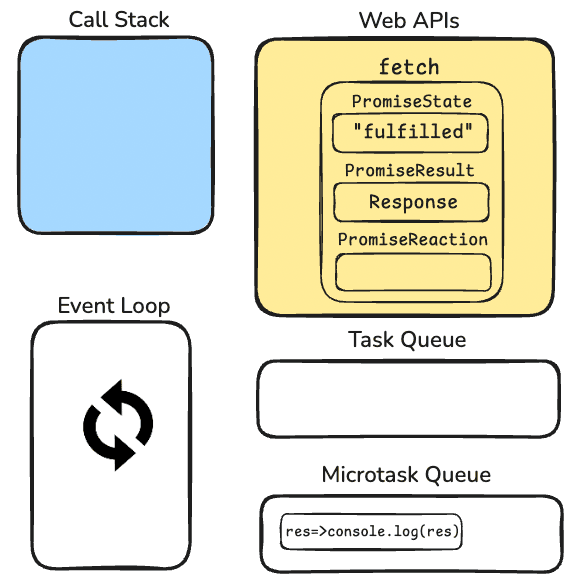
Since call stack is empty, the event loop will check the microtask queue and moves our function to call stack. Our function gets executed and it logs the result that we got from the server.
Now, let's do one final example and let's see if you got it right. Before you check the answer, try to solve it yourself first.
We have the following code;
Promise.resolve().then(() => console.log(32));
setTimeout(() => console.log(9), 5);
queueMicrotask(() => {
console.log(11);
queueMicrotask(() => console.log(4));
});
console.log(3);
What will be the output?
The correct answer will be;
3 32 11 4 9
First, we have Promise.resolve(), this line will create a promise object but it will instantly be resolved. Since promise is already resolved, .then function will directly be pushed to microtask queue.
Then, setTimeout will initiate the timer and after 5 milliseconds have passed, callback function will be pushed to task queue.
Then, we have queueMicrotask which will push the function into microtask queue.
In the last line, we have console.log(3) so that function will directly go into call stack and be executed. So 3 will be logged to the console.
Our script is done and call stack is empty. Now event loop will check the microtask queue first. It will see the first function that is in the microtask queue is console.log(32) so 32 will be logged to the console.
Now, it goes to other function in the microtask queue which is queueMicrotask(()=>{ console.log(11); queueMicrotask(()=>console.log(4)) }); this one. Now it will take this function to the call stack and will log 11 to the console. Then it sees another function that needs to be taken to the microtask queue. It takes ()=>console.log(4) and pushes it to the microtask queue. Since microtask queue is still not empty, we will not go to task queue and first finish the microtask queue. That's why 4 will be printed on the screen.
Finally, our microtask queue is empty and now event loop can go to task queue to move that function to call stack. It will print 9 to the console.
Now, you have a solid understanding how javascript actually works behind the scenes.
In this blog, we've basically covered how the Event Loop orchestrates tasks across the Call Stack and other runtime components. However, it's important to realize that the commands we write like console.log don't simply land on the Stack as raw text, as you might assume... The V8 engine must first interpret and transform them into something the machine understands. To see how this translation from source code to executable bytecode actually happens, you can check out this blog where we take a deep dive into how the V8 engine turns your human-readable code into something machines can actually use. - How V8 JavaScript Engine Transforms Your Code: From Human-Readable to Machine Code
Was this blog helpful for you? If so,